无论是在商用的midjourney V5,还是在基于开源的stable diffusion的text to image的AI生图中,一个难以绕过去的问题是,人物手部姿势的稳定生成。一个容易遇到的问题场景是,当用户使用精心设计的prompt和denoising parameter生成一张高分辨率的图片,从整体构图,到色彩、人物神情等都比较的满意的时候,却发现人物的手部姿势发生扭曲,最常见的是产生六指。如果此时通过调整参数如textural inversion、LoRA和controlNet等,又会改变生成图像的分布,达不到原来的生成效果。另外一种方案是使用inpainting的方式将畸形的手部区域进行重绘,但是如果没有合适的方法和技巧,仅仅靠不同的随机数搜索好的手姿的分布,其搜索范围将会很大,并且在设备有限的情况下比较耗时。如何设计一个高效的inpainting的工作流将是一个需要不断探索和实践的方向。
在这篇文章中,本人主要探索仅仅使用AI工具对手姿进行修复的工作流,不涉及其他工具如photoshop的使用(主要是没探索出来,用了效果一般)。以下是我复现的效果。

原理
从high-level insight来看stable diffusion的原理,本质上是从一个先验分布(如高斯分布)到数据分布的映射,在text-to-image的任务中,主要通过文本来控制如何进行映射;如果将其看成一个优化问题,则是通过text这种条件信息来约束解空间。
SD-based Inpainting的原理
与基于卷积使用临近区域进行inpainting机理不同,基于stable diffusion的inpainting方法更类似于使用GAN inversion在生成模型的隐空间搜索可行解。具体而言,stable diffuision通过denoising strength的参数控制图片的diffusion process的程度,并重新通过solver来搜索潜在解空间。其工作的原理是,如下图所示,加噪后的图片将作为图像条件信息约束解空间,denoising strength越大,则图像信号越小,solver的迭代次数也越多,那么解空间的范围越大。当solver的迭代次数为0的时候,将原图和inpainting的图片通过mask进行融合,另外边缘区域将通过gaussion blur等一些后处理使得拼接结果更加平滑。

与基于GAN inversion的方法不同,基于stable diffusion的方法更加灵活且具有可拓展性,原因在于,stable diffusion的模型设计使得其在denoising的过程中可以添加更多条件信息以约束解空间。
在修复坏手的场景下,只通过文本的信息是难以对手部实现更加精细化的控制的。根据之前翻阅的博客来看,目前处理坏手的主要有一下几种方法:Textural Inversion、LoRA、ControlNet,其主要原理是通过在denoising model的不同组件中加入条件信息以在denoising process控制生成结果,以下将逐一简要介绍原理。另外也有结合photoshop的方法直接在原图上修改手部姿势,这相当于直接修改图像分布,通过stable diffusion对色彩、光影等分布进行调整,使之更好融入原图中,但是该方法暂不在本文中进行探讨。
Textural Inversion
基于embedding方法(本质上是基于textural inversion),其主要思想是通过在text encoder(如CLIP)的词表中注入新的概念(prompt) ,并通过对应的图片的来微调该概念对应的word embedding。与直觉有一点差异的是,在应用中,注入的新的概念不是好手,并通过好手的图片来微调;注入的新的概念往往是坏手,亦或者是坏的肢体。个人感觉这样的做法是因为:其一,模型并对于好手的概念是比较难学习到;其二,坏手的图片很容易在生成图片的过程中获得,因此数据量比较充足。因此,在使用的时候需要将坏手的概念加入到negative prompt中,也就是提供反向条件信息来约束解空间。
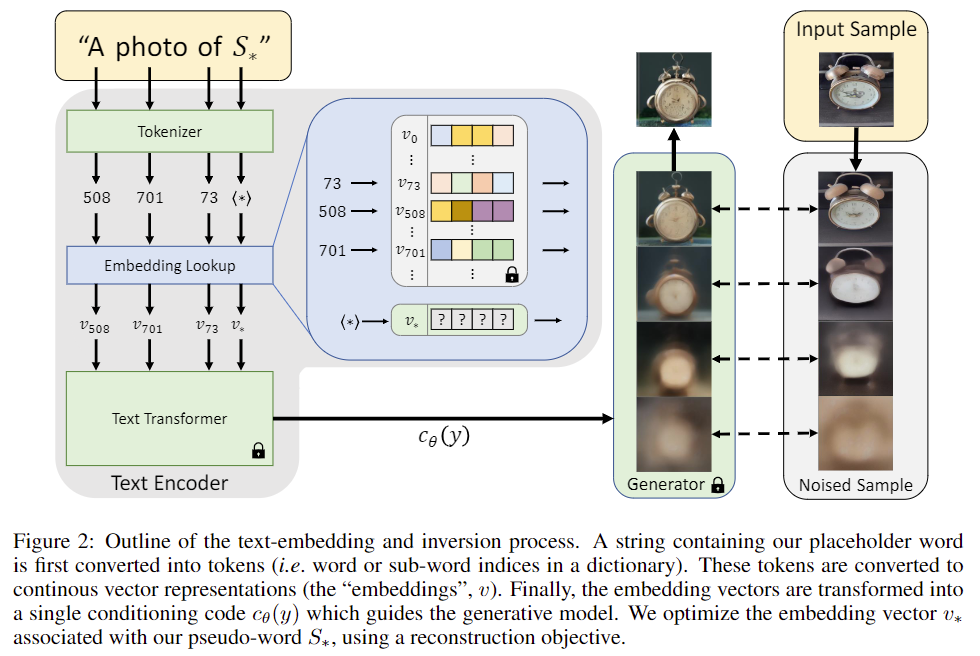
这种方式的对于解空间的限制仅仅来自于文本,因此控制效果比较一般,只能控制手体面积占画面比重较大的图像,对于复杂手姿效果有限。
LoRA
基于LoRA及其变种(如LyCORIS)的方法,这类方法的主要思想是在diffusion model的U-net网络中,transformer模块的to_k、to_q、to_v的全连接层,加入一个可训练的bottlenet形状的全连接的”indentity mapping”(这个表述是生动但不严谨的)。在应用中,往往需要额外分布的数据进行训练来微调diffusion model的LoRA部分权重。
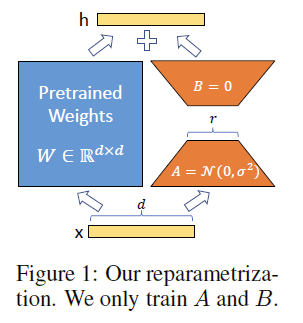
本次实践中主要用到修手的LoRA是hipoly_3dcg_v7-epoch-000012,LyCORIS是GoodHands-beta2,其中LyCORIS需要在stable diffuion中安装额外的插件a1111-sd-webui-lycoris。
ControlNet
基于ControlNet的方法。与LoRA的思想类似也是添加额外的网络分支进行训练,而与LoRA不同的是,ControlNet可以输入额外的条件信息,如(depth map、edge、openpose)等,其次,从参数量的角度来说,ControlNet的相对更大,因此控制力度更强。
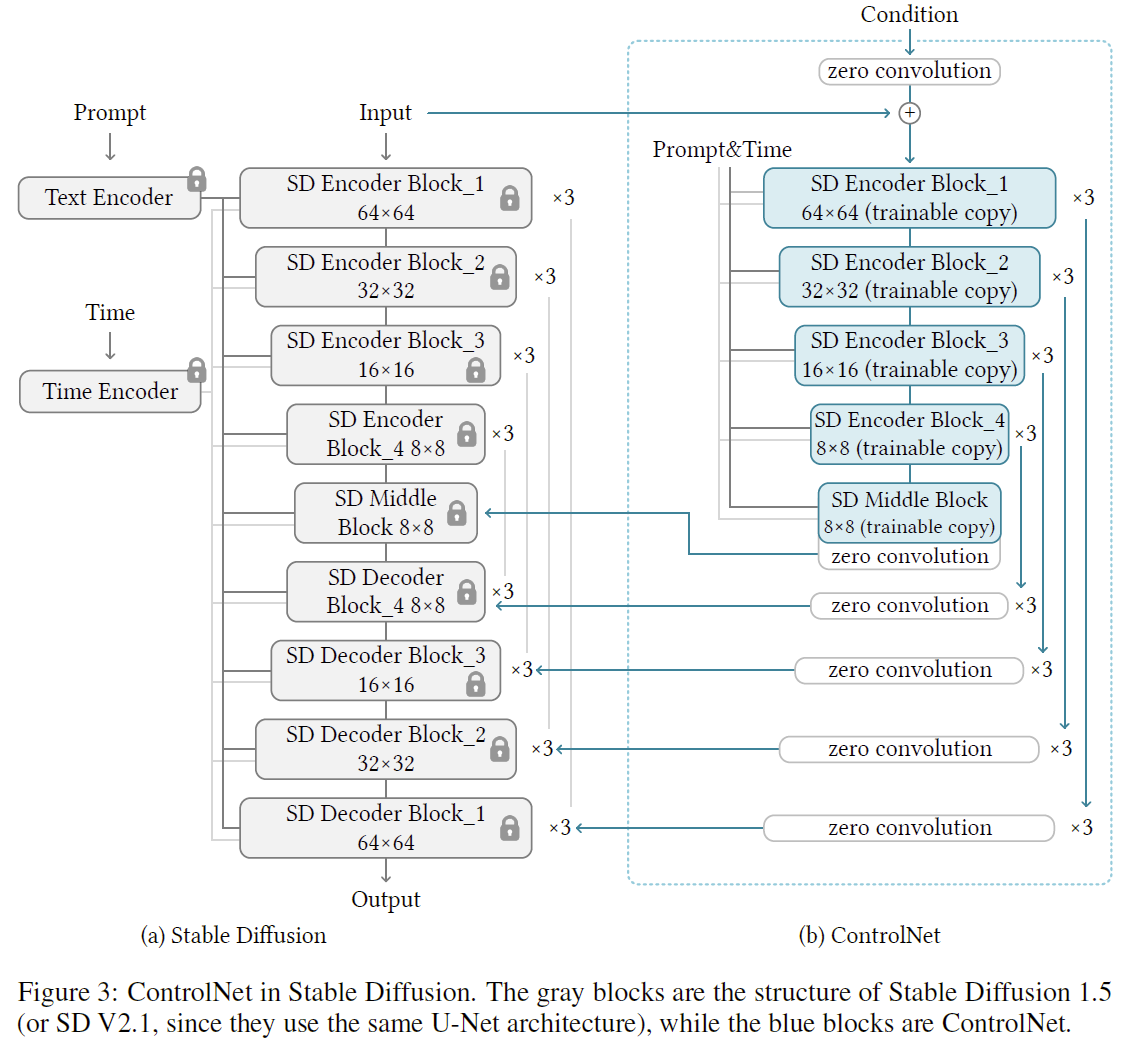
上述讲述原理的论文有:
[1] Textural inversion: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
[2] LoRA: LoRA: Low-Rank Adaptation of Large Language Models
[3] ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
分析
Parameters
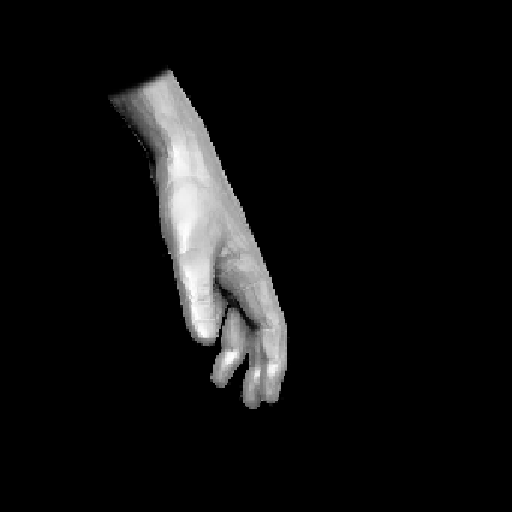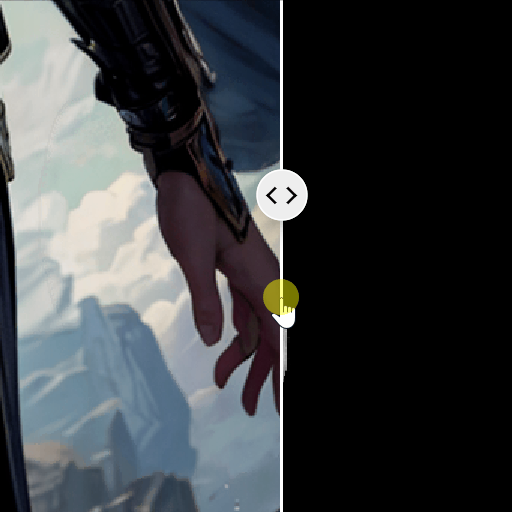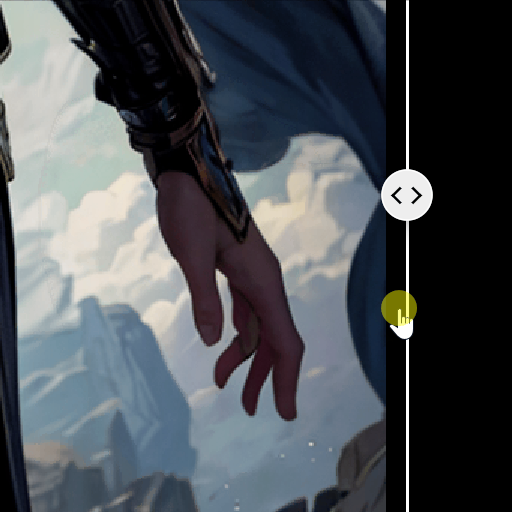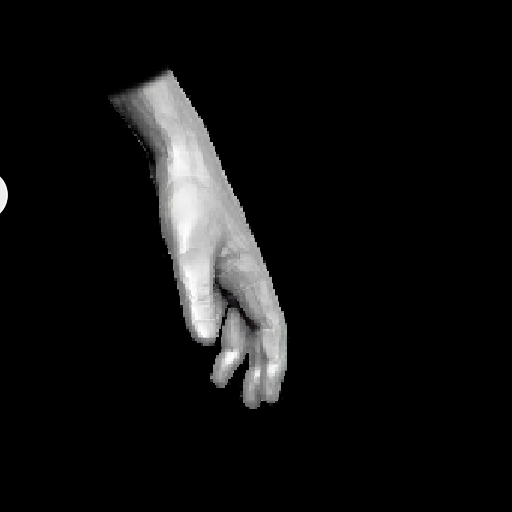
以下这张图可以容易通过下面的参数生成,值得注意的是其中使用到的Stable Diffusion,embedding,LoRA需要在huggingface或者civitai上下载并放置到/model下对应模型类型的文件夹,可以看到该图右边的手是存在六指的:
1 | official art,unity 8k wallpaper,ultra detailed,masterpiece,best quality,1 woman,(extremely detailed),dynamic angle,Mysterious expression,wind effect,fantasy background,rim lighting,side lighting,cinematic light,ultra high res,8k uhd,film grain,best shadow,delicate,RAW,light particles,detailed skin texture,detailed armor texture,detailed face,intricate details,ultra detailed,bright,strong,<lora:sxz-death-knight:0.6>,(silver armor),holding spear,pauldrons,((yellow hair)),glowing blue eyes,bangs,blue cape,fantasy,(realistic),atmospheric,<lora:hipoly_3dcg_v7-epoch:0.3>,<lora:add_detail:1> |

Pipeline
根据参数和我在实验中的分步拆解text-to-image中的执行过程,这样图片的生成存在这样的pipeline:
- 首先,是在大小为的尺度上以30的步长使用text-to-img方法生成图像内容。
- 其次,使用一个类似于ESRGAN的模型对图像进行超分辨率重建。
- 最后,在0.5的denoising strength以15的步长进行img-to-img变换,相当于在高分辨率尺度上对图像进行refinement。
可以看到从低分辨率图像开始人物的左手就存在六指问题,即便使用卷积网络进行超分辨率重建以及使用stable diffusion进行高分辨率重建也没有修复这个问题,其中后者六指的细节还增加了。

由于,我认为这个参数设定下生成的人物神情恰好击中了我的审美,因此,如果在不大幅修改图像人物神情分布的情况下修复坏手是一件值得思考的问题。从前面的原理来看,可以通过textural Inversion、LoRA和ControlNet等多种方式来约束stable diffusion的解空间。需要分析的是,在上述的pipeline的哪个部分添加怎么样的控制不会影响既定分布同时又能修复坏手问题?为此我做了以下实验。
Text-to-img
如果使用text-to-image的方法,首先需要排除排除Textural Inversion和LoRA,因为在原有基础的parameters的设定下,修改任意word embedding和LoRA都会改变图像分布。那么是否可以使用ControlNet的方式进行控制,这里我主要尝试的方式是depth map,为此需要下载sd-webui-depth-lib插件以方便添加手部控制。由于这个插件自带的手部深度图比较有限,我在civitai上发现了一个更加丰富的手部深度图库:900 Hands Library for Depth Library | ControlNet。对比原图使用了作图这样的手势,并根据原图摆放到对应位置以生成深度信息图:

在text-to-image的配置ControlNet配置该条件信息输入网络中,如下所示:
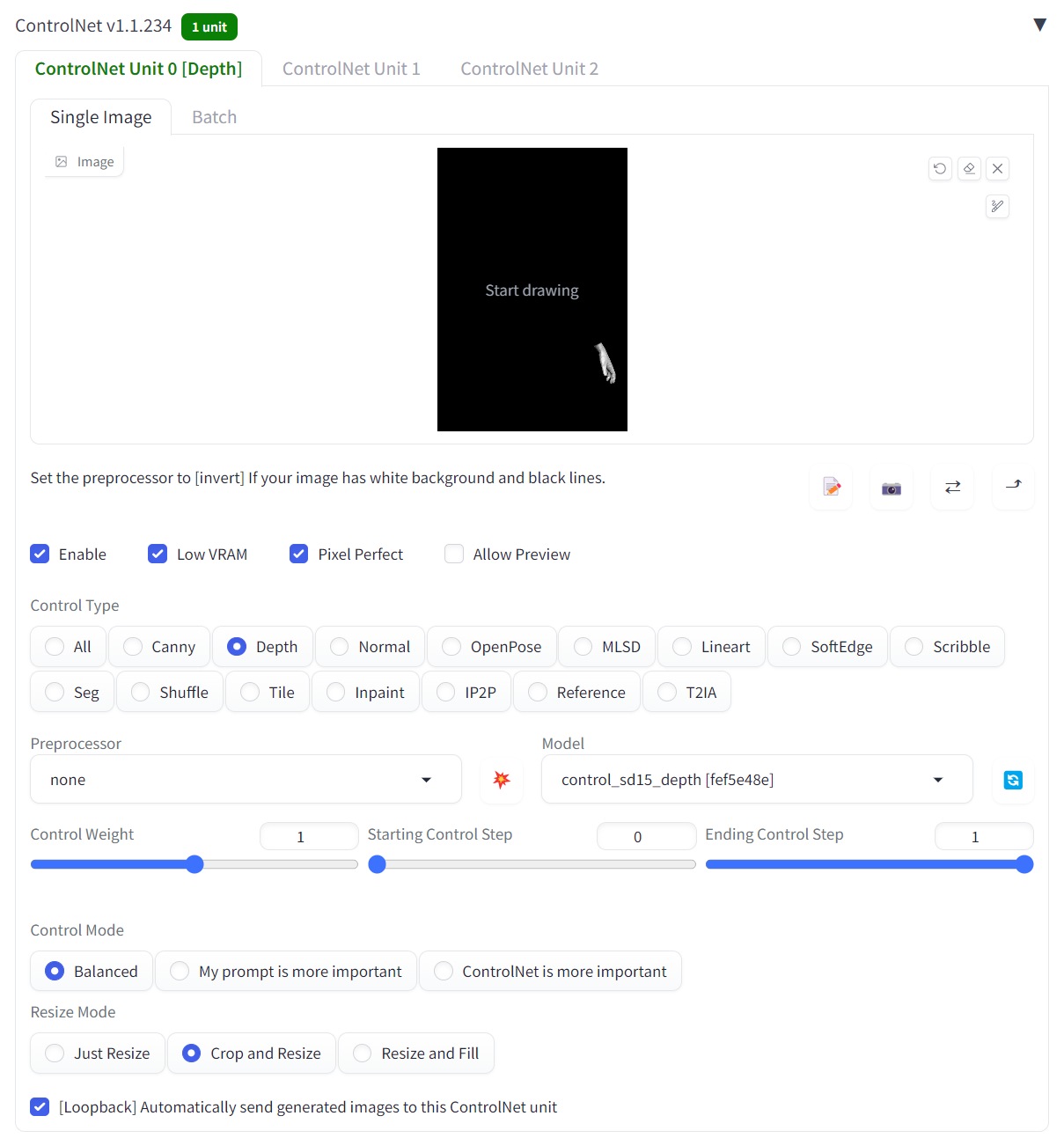
当然如果显存充足的情况下,可以使用不同的条件信息如canny和Openpose追加控制,见t2iadapter和coadaper介绍的方法,本人实践这两种方法在单一模型控制下效果不如ControlNet。
然而,很不幸这种方法也会极大地修改图像的分布,同时手姿问题也没有很好地解决:

注:这里的提及论文是:
[4] T2I-Adapter: T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
[5] Coadaper: Composer: Creative and Controllable Image Synthesis with Composable Conditions
Img-to-img
那么既然上述方法行不通,另外一种想法就是,在Refinement的过程中使用ControlNet的添加约束,以类似的设定进行实验。然而,这种方式也会修改图像的分布,同时面部细节也会有塑料感:

实践
因此,更好的办法就是在Example.png的图片上进行区域重绘,然而实验中发现通过简单的mask和inpainting难以实现期望的效果,根据前面对SD-based inpainting原理的分析,需要思考的是,到底什么样参数设定会影响实现预期的inpainting?
首先需要思考的是,这么多parameters哪些是可以是需要保留的,哪些是可以修改的。从原理上来说,prompt、negative prompt、sampling methods、sampling steps等这些大部分是不宜修改的,否则会影响最后生成图像的分布。但是,值得思考的是否可以添加合适的条件输入,去除不合适的条件输入来更好地约束解空间,以下是一些思考和修改:
LoRA:
- 通过开源社区发现,GoodHand对于整图的手部生成有较大的帮助,为此加入该LyCORIS可能对inpainting结果有帮助。
- add_detail,虽然该LoRA可以增加图像的细节信息,但是实践中发现,该LoRA的加入会助生多余的手指,因此在inpaiting的过程中将其去处。
ControlNet:
- 正如Text-to-img章节中所分析,由于ControlNet能帮助约束解空间,因此类似于Text-to-img和img-to-img,在inpainting的时候ControlNet需要保留,并且可以适当增加ControlNet部分的权重如
1.2,以及设定ControlNet is more important。
Dynamic Denoising Strength:
- 前面说到,Denoising Strength越大,解空间的范围越大。因此当图像中需要inpainting的区域离期望分布较远时,需要使用较大Denoising Stength(如0.75)来修改原图的分布,当inpainting的区域离期望分布较接近时,该用较小的Denoising Strength(如0.5)对原图的分布进行调整。
Adetailer:
使用Adetailer,其潜在原理是通过检测和分割的思路找到图像中手的位置,可以设定针对手的prompt进行重绘。这里我使用
hand_yolov8n.pt网络结合以下的negative prompt对手部进行优化,基本上是embedding。1
badhandsv5-neg,badhandv4,EasyNegative,easynegative,ng_deepnegative_v1_75t,verybadimagenegative_v1.3
batch count and Loop back:
- 一种是使用
batch count,相当于在原来的seed上递增,通过不同的随机数搜索好手的分布。 - 另外一种是使用
Script中的Loop back,以recurrent的方式迭代式将输出送到输入中。 - 前者像广度搜索解空间,后者像深度搜索解空间,可以结合两者使用。
接下来就是概率抽奖环节,由于使用较大的denoising strength,所以在过程中生成出来的图像手部纹理具有较大差异,甚至可能不是手的纹理,我只能说:“淡定,骚年,这是正常滴”,或许可能调低denoising strength以获得更稳定的结果。
实现案例

此处我以input为输入,设置denoising strength=0.65(注:由于暂时不清楚Loopback和Inpainting的执行工作流,所以上下两处的denoising strength均设为0.65),执行30次Loop back,使用Aggressive的策略作为Denoising strength curve:
当然也可以使用batch count的方式搜索解空间,随后执行denoising strength为0.5、0.4、0.3等,使用不同denoising noise调整解空间,如果发现手部增加莫名的细节可以关闭Adetailer,结果图如下:

对比图如下:
总结
综上,本方法的核心想法是,在inpaintng修复手的时候:
- 加入或删除某些embedding和LoRA,取决于具体实验分析。
- 使用ControlNet控制,以深度图或者openpose,取决于获取的难易程度。
- 使用递减的denoising strength,但图片中手的姿势与期望姿势较大的时候,使用大的denoising strength,反之使用小的。
- 使用Adetailer检测手的部分,写一手部专用的prompt和negative prompt调整手的生成好坏。
总体来说,inpainting修复手的成功与否,较大一部分取决于期望手姿的复杂度:如果手部不同手指重合在一起,那么要让模型生成这样的分布是比较困难的,如果手指棱角分明的区分开,那么达到这样的重绘效果,是相对来说比较简单的,当然难易程度或多或少取决于手部周围的背景复杂度。
优越性:现有方法虽然能实现仅仅通过AI方法完成较高质量的手部修复和重绘,同时在有限的显存(8GB)条件下也能进行。
局限性:现有方法自动化程度不高,需要人为设置的条件参数较多,同时随机搜索分布的过程比较耗时。
Reference and resource
Paper:
[1] Textural inversion: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
[2] LoRA: LoRA: Low-Rank Adaptation of Large Language Models
[3] ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
[4] T2I-Adapter: T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
[5] Coadaper: Composer: Creative and Controllable Image Synthesis with Composable Conditions
Denoising Model:
Upscaler:
[1] 4x-UltrSharp
LoRA:
[1] add_detail,用来增加细节。
[2] hipoly_3dcg_v7-epoch,修手的偏方。
[3] sxz-death-knight,魔兽世界的骑士风格。
LyCORIS:
[1] GoodHand,修手的模型。
Textural Inversion(主要是用来减少坏手概率):
[3] easynegative
[4] badhandv4
[5] badhandsv5-neg
Depth Map: